논문 출처 : https://arxiv.org/abs/2106.01345
코드 출처 : https://github.com/kzl/decision-transformer
이 논문이 쓰여지게 된 배경은 ViT의 출현( https://arxiv.org/abs/2010.11929 )과 관련이 있어 보인다.
위 Vision Transformer Architecture를 살펴보면 이미지를 고정된 크기의 Patch로 나누어 준 후 Position Embedding화하여 Sequential하게 Transformer의 인코더에 Input값으로 넣는다.
입력값으로 들어간 이미지를 일반적인 Transformer Input 값과 동일하게 Data Transformation을 수행한 후 classification token을 더해준다. 이 정보를 이용해 이미지 class를 예측하기 위함이다.
ViT는 참고이고 이제 우리가 보고자 하는 Decision Transformer논문을 살펴보자!!!
기존의 RL은 State Transition Probability를 풀어가는 방법론으로 value function(value of state)와 Policy Gradients를 활용하는 것이 일반적이었으나, 본 논문에서는 기존의 State Transition 자체를 Trajectory로 가정하고 이를 Trajectory Model이나 GPT2 Model로 conditional sequence modeling으로 캐스팅하자는 아키텍처로 접근해 보았다.

설명이 좀 어렵다면 위의 Neural Network Architecture를 기반으로 설명하도록 하겠다.
이 논문을 Research하게 된 이유는 강화학습을 활용하여 시장 국면을 탐지해서 Dynamic Asset Allocation을 할 수 있는지를 가늠해 보고자 선택하게 되었다.
다양한 강화학습 논문들을 리뷰하고 살펴보며 든 생각은 아래와 같다.
첫번째, 기존의 Reinforcement Learning은 근본적으로 observation space와 action space정의가 어렵다는 문제를 가지고 있다. 이는 state action pair를 정의하는 policy network를 구성하기 어렵다는 것과 일맥상통한다.
두번째, episode별 reward정의가 어렵다. 이는 episode를 구분할 구간을 판정하기가 어렵고 이는 시장 국면에 따른 range detection의 영역이므로 일정 부분 사람의 판단이 필요하다.
하지만 사람마다 시장 국면을 바로보는 기준점이 다르다.
이 논문에서는 위의 문제를 conditional sequence modeling으로 casting하여 풀어보려고 하는 시도가 보였고, 이게 바로 decision transformer architecture가 출현하게 된 배경이다.

하기 코드를 보면 바로 알 수 있지만 States, Actions 및 returns(rewards)는 modality-specific linear embeddings에 제공되고 positional episodic timesteps encoding이 추가된다.
토큰은 causal self-attention mask를 사용하여 자동회귀적으로 동작을 예측하는 GPT 아키텍처에 공급된다.
class SequenceTrainer(Trainer):
def train_step(self):
states, actions, rewards, dones, rtg, timesteps, attention_mask = self.get_batch(self.batch_size)
action_target = torch.clone(actions)
state_preds, action_preds, reward_preds = self.model.forward(
states, actions, rewards, rtg[:,:-1], timesteps, attention_mask=attention_mask,
)
act_dim = action_preds.shape[2]
action_preds = action_preds.reshape(-1, act_dim)[attention_mask.reshape(-1) > 0]
action_target = action_target.reshape(-1, act_dim)[attention_mask.reshape(-1) > 0]
loss = self.loss_fn(
None, action_preds, None,
None, action_target, None,
)
self.optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(self.model.parameters(), .25)
self.optimizer.step()
with torch.no_grad():
self.diagnostics['training/action_error'] = torch.mean((action_preds-action_target)**2).detach().cpu().item()
return loss.detach().cpu().item()
- Introduction
최근 작업은 transformer가 언어에 효과적인 zero-shot generalization 및 out-of-distribution image generation을 포함하여 semantic concepts의 high-dimensional distributions를 대규모로 모델링할 수 있을을 보여주었다. 이런 모델의 성공적인 적용을 다양한 곳에 적용할 수 있지는 않을까 하여 이 논문에서는 강화 학습(RL)으로 공식화된 sequential decision making문제에 대해 적용 방안을 찾아보고자 한다.
전통적인 RL 논문에서 정의된 states, action and rewards 들을 generative trajectory modeling방법론을 활용하여 대체가 가능한지 연구하고, temporal difference(TD) learning과 같은 conventional RL알고리즘을 통해 policy를 훈련하는 대신 sequence modeling objective를 사용하여 수집된 데이터에 대해 transformer models를 훈련합니다.
이를 통해 long term credit assignment을 위한 bootstrapping의 필요성을 우회할 수 있으므로 RL을 불안정하게 하는 “deadly triad” 중 하나를 피할 수 있다. 또한 일반적으로 TD 학습에서 수행할 때 나타나는 바람직하지 않는 근시안적 행동 유발할 수 있는 방식인 미래 보상을 discounting할 필요가 없다.
long sequences를 모델링하는 입증된 능력 외에도 transformer에는 다른 장점이 있다.
보상을 천천히 전파하고 “주의를 산만하게 하는(distractor)” 신호에 취약한 Bellman backups와 달리 transformers는 self-attention을 통해 직접 credit assignment를 수행할 수 있다. 이를 통해 transformers는 sparse하거나 산만한 보상(distracting rewards)이 있는 경우에도 여전히 효과적으로 작동할 수 있다.
마지막으로 empirical evidence는 transformer modeling approach방식이 행동의 광범위한 분포를 모델링하여 더 나은 generalization and transfer를 가능하게 할 수 있음을 보여준다.
이 논문에서는 오프라인 RL에 기반하여 가정해 보자! 이 환경에서 에이전트는 차선의 데이터(suboptimal data)에서 학습 정책을 수행하여 fixed, limited 경험에서 최대한 효과적인 행동을 생성한다. 이 작업은 전통적으로 error propagation과 value overestimation으로 인해 까다로운 작업이다. 그러나 Sequence Modeling Ojbect로 훈련방식을 바꾸게 되면 자연스럽게 이뤄질 수 있다.
state, actions and returns의 sequence에 대한 autoregressive model을 훈련함으로써 policy sampling을 autoregressive query할 “skill”인 정책의 전문 지식을 지정할 수 있다.
아래 그림과 같이 그래프에서 최단 경로를 찾는 작업을 가정하여 reward는 agent가 goal node에 있을 때 0, 그렇지 않으면 -1로 가정하고, GPT 모델을 훈련하여 returns-to-go (future rewards의 합), states, and actions의 sequence에서 다음 토큰을 예측하는 형태로 보면 된다.
전문가 시연 없이 random wark 데이터에 대해서만 훈련하면 가능한 가장 높은 return을 생성하기 위해 prior를 추가하여 테스트 시간에 optimal trajectories을 생성할 수 있다. 따라서 Sequence Modeling 도구를 사후 반환 정보(hindsight return information)과 결합하여 dynamic programming없이 policy improvement를 달성하게 한다.
강화학습으로 제시된 고정 그래프에 대한 최단 경로를 찾는 예시
훈련 데이터 세트는 random work trajectories와 노드당 반환(per-node return-to-go)로 구성된다.
시작 상태를 조건으로 하고 각 노드에서 가능한 최대의 return을 생성하는 Decision Transformer로 최적 경로를 Sequencing함
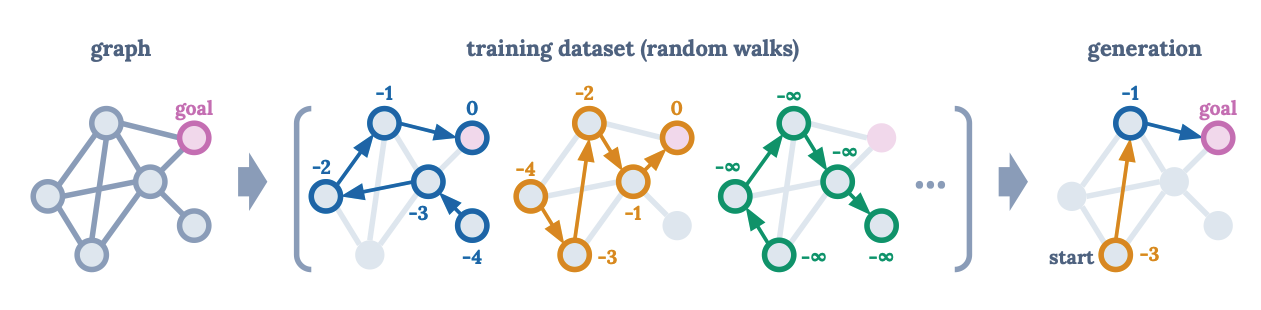
위 그림을 통한 관찰을 통해 연구의 동기를 얻었고 GPT아키텍처를 사용하여 trajectories을 autoregressively로 모델링하는 Decision Transformer를 제안한다. 이 제안된 모델에 대하여 Atari, OpenAI Gym, Key-to-Door환경의 offline RL benchmarks에서 Decision Transformer를 평가하여 sequence modeling이 policy optimization을 수행할 수 있는지 여부를 해당 논문에서 연구해 보겠다. 연구 결과 dynamic programming을 사용하지 않은 Decision Transformer가 state-of-the-art model-free offline RL알고리즘의 성능과 일치하거나 그 이상임을 보였다.
또한 long-term credit assignment가 필요한 작업에서 Decision Transformer는 RL기준선을 능가한다. 이 결과를 통해 Sequence Modeling과 transformers를 RL과 연결하는 것을 목표로 하고 sequence modeling이 RL에 대해 강력한 알고리즘의 전환점 역할을 할 수 있을지를 기대한다.
2. Preliminaries
2.1 Offline reinforcement learning
강화학습은 적절한 exploration과 exploitation을 통해서 어떤 task에 대해 trial-and-error방식으로 학습할 수 있는 대표적인 기법이다. Batch Reinforcement Learning(Batch RL)이라고도 알려져 있는 Offline Reinforcement Learning(Offline RL)은 이런 강화학습의 부류 중 하나로, exploration없이도 정해진 배치만큼의 데이터만 가지고도 에이전트를 학습할 수 있다. 다르게 표현하자면, 고정된 데이터셋만 가지고 극도로 exploitation을 수행하는 것이다.
실제 환경에서 로봇을 가지고 exploration을 한다는 건 로봇 내에 장착되어 있는 하드웨어나 부가적은 요소들에 손상을 가져올 수 있다. 또한 Offline RL자체가 어쩌면 exploitation으로부터 exploration을 도출하는 것이기 때문에, 다른 강화학습 알고리즘들 간의 exploitation 성능을 비교할 수 있는 표준 척도가 된다.
Offline RL에서는 환경 상호 작용을 통해 데이터를 얻는 대신에 arbitrary policies의 trajectory rollouts로 구성된 일부 fixed limited dataset에 접근할 수 있다. 이 설정은 agents가 환경을 탐색하고 추가 피드백을 수집할 수 있는 능력을 제거하는 것임으로 어려운 일이다.
timestep t에 trajectory의 return은
timestep으로부터 산출된 future rewards의 합
reinforcement learning안에서의 goal은 policy를 학습하는데 있고 이는 MDP내에서 expected return을 maximizes하는데 있다.

2.2 Transformers
트랜스포머는 RNN을 사용하지 않지만 기존의 seq2seq처럼 인코더에서 입력 시퀀스를 입력받고, 디코더에서 출력 시퀀스를 출력하는 인코더-디코더 구조를 유지합니다. 다른 점은 인코더와 디코더라는 단위가 N개 존재할 수 있다는 점이다.
이전 seq2seq는 인코더와 디코더에서 각각 하나의 RNN이 t개의 시점(time-step)을 가지는 구조였다면, 이번엔 인코더와 디코더라는 단위가 N개로 구성되는 구조입니다.

1. Encoder Self-Attention : Query = Key = Value
2. Masked Decoder Self-Attention : Query = Key = Value
3. Encoder-Decoder Attention : Query : Decoder Vector <-> Key = Value : Encoder Vector

Transformers는 sequential data에 효율적인 모델을 위한 Architecture이다. 이 모델은 residual connections를 self-attention layers에 쌓이게 구성되어졌다.
i번째 token은 선형 변환을 통해
에 mapping됩니다.
self-attention layer의 i번째 출력은 쿼리 Qi와 다른 키 Kj 사이의 정규화된 내적에 의한 값 Vj에 가중치를 주어 주어짐

이것은 쿼리의 유사성과 키 벡터(내적 최대화)를 통해 상태-반환 연결을 암시적으로 형성함으로써 레이어가 “크레딧”을 할당할 수 있도록 합니다.
이 작업에서는 GPT아키텍처를 사용한다. 이 아키텍처는 causal self-attention mask로 transformer architecture를 수정하여 autoregressive generation을 가능하게 하고 n개의 토큰에 대한 summation/softmax를 sequence의 이전 토큰으로 대체합니다.
Autoregressive
GPT-2는 디코더 스택만 사용한 모델
GPT-2는 자기 회귀 모델(auto-regressive model)입니다. 자기 회귀 모델이란 이전의 출력이 다음의 입력이 되는 모델을 의미한다. BERT는 자기 회귀 모델이 아니다.
평범한 Self-Attention을 사용하여 자기 회귀 능력을 포기한 BERT는 다음 단어의 예측 능력은 덜 하지만, 맥락 정보를 충분히 고려할 수 있다.
반면, Masked Self-Attention을 사용하는 자기회귀 모델인 GPT-2는 다음 단어의 예측 능력은 뛰어나지만, 해당 단어 이후에 있는 맥락 정보들을 이용할 수 없다.
3. Method
Transformer 아키텍처에 대한 최소한의 수정으로 autoregressively로 trajectory을 모델링하는 Decision Transformer를 제시
trajectory representation
trajectory representation을 선택할 때 주요 요구 사항은 transformers가 의미 있는 패턴을 학습할 수 있어야 하고 테스트 시간에 조건부로 actions을 생성할 수 있어야 한다는 것이다.
모델이 과거의 보상이 아닌 미래의 원하는 return을 기반으로 actions을 생성하기를 원하기 때문에 보상을 모델링하는 것은 중요하지 않다.
결과적으로 보상을 즉각적으로 주는 대신에 returns-to-go를 모델에 반영하고 싶다.
이것은 autoregressive training 및 generation에 적합한 trajectory representation으로 이어진다.
테스트 시간에 원하는 성능(예: 성공의 경우 1, 실패의 경우 0)과 환경 시작 상태에 대한 생성을 시작하기 위한 conditioning information으로 지정할 수 있다. 현재 상태에 대해 생성된 액션을 실행한 후 달성한 보상만큼 target return을 감소시키고 episode가 종료될 때까지 반복한다.
Architecture
총 3,000개의 토큰(one for each modality : return-to-go, state, or action)에 대해 마지막 K timesteps을 Decision Transformer에 제공한다.
토큰 임베딩을 얻기 위해 임베딩 차원에 raw input을 투영한 후 Layer정규화를 수행하는 각 양식에 대한 선형 Layer를 학습한다. 시각적 입력이 있는 환경의 경우 상태는 선형 레이어 대신 컨볼루션 인코더에 입력한다. 또한 각 시간 단계에 대한 임베딩이 학습되어 각 토큰에 추가한다. 이는 하나의 시간 단계가 3개의 토큰에 해당하므로 transformer에서 사용하는 standard positional embedding과는 다르다. 그런 다음 토큰은 autoregressive modeling을 통해 미래 action tokens을 예측하는 GPT모델에 의해 처리된다.
Training
offline trajectories의 dataset이 제공된다. dataset에서 sequence 길이 k의 mini batch를 sampling합니다. 입력 토큰 St에 해당하는 예측 head는 이산 동작에 대한 cross-entropy loss또는 continuous actions에 대한 mean-squared error로 예측하도록 훈련되고 각 시간 단계에 대한 손실이 평균화된다.
하지만 이 연구는 향후 작업에 대한 흥미로운 연구가 될 수는 있으나 성능을 향상시키기 위한 factor 즉 states 또는 returns-to-go할 예측을 찾지 못했다.
4. Evaluations on Offline RL Benchmarks
이 섹션에서는 dedicated offline RL 및 imitation learning 알고리즘과 관련된 Decision Transformer의 성능을 알아보자
특히 Decision Transformer 아키텍처는 기본적으로 모델이 없기 때문에 TD learning을 기반으로 하는 model-free offline RL 알고리즘을 주요 비교 대상으로 선정하였습니다. 또한 TD learning은 샘플 효율성을 위한 RL의 지배적인 패러다임이며 많은 모델 기반 RL 알고리즘에서 서브루틴으로 사용됩니다.
TD learning : 이러한 방법의 대부분은 action-space constraint 또는 value pessimism을 사용하여 표준 RL 방법을 나타내는 Decision Transformer와 가장 충실하게 비교 가능하다.
state-of-the-art model-free method는 우리의 주요 비교 역할을 하는 Conservative Q-Learning(CQL)이다. 또한 BEAR 및 BRAC와 같은 prior model-free RL 알고리즘과도 비교합니다.
Imitation learning : 이 체제는 유사하게 Bellman backups이 아닌 훈련에 supervised losses을 사용한다. 그리고 discrete(Atari)와 continuous(OpenAI Gym) 제어 작업을 모두 평가한다.
전자는 high-dimensional observation spaces을 포함하고 long-term credit 할당이 필요한 반면 후자는 다양한 작업 집합을 나타내는 세밀한 연속 제어가 필요하다.
4.1 Atari
Atari 벤치마크는 높은 차원의 시각적 입력과 행동과 결과 보상 사이의 지연으로 인한 credit assignment의 어려움 때문에 도전적인 bm이다. Agarwal et al.에 따라 DQN 재생 데이터 세트의 모든 샘플 중 1%에 대해 method를 평가합니다.
훈련 중 온라인 DQN 에이전트가 관찰한 5천만개의 transitions 중 50만 개를 나타냅니다. 우리는 3개의 seeds의 mean과 standard deviation을 report합니다.
4.2 OpenAI Gym

D4RL 벤치마크의 continuous control tasks를 고려합니다. 또한 벤치마크의 일부가 아닌 2D reacher 환경을 고려하고 D4RL 벤치마크와 유사한 방법론을 사용하여 데이터 세트를 생성합니다. Reacher는 goal-conditioned task이고 sparse rewards하므로 표준 이동 환경(HalfCheetah, Hopper 및 Walker)과 다른 설정을 나타낸다.
5 Discussion
5.1 Dose Decision Transformer perform behavior cloning on a subset of the data?
5.2 How well does Decision Transformer model the distribution of returns?
5.3 What is the benefit of using a longer context length?
5.4 Does Decision Transformer perform effective long-term credit assignment?
5.5 Can transformers be accurate critics in sparse reward settings?
5.6 Does Decision Transformer perform well in sparse reward settings?
5.7 Why does Decision Transformer avoid the need for value pessimism or behavior regularization?
5.8 How can Decision Transformer benefit online RL regimes?
