
DDPG(Deep Deterministic Policy Gradient)란 무엇인가?
(논문 참고 : https://deepmind.com/research/publications/deterministic-policy-gradient-algorithms/ )
continuous action domain을 가지 시스템에서 원하는 목적을 달성하도록 제어를 하는 알고리즘으로 actor-critic model-free policy gradient 방법을 적용하는 기술
Deep이라는 단어를 사용한 이유는, DQN과 같이 Actor와 Critic approximation function에 neural network를 사용하였기 때문이다.
DDPG의 의미
DQN이 가지는 큰 의미는 State/Observation space dimension이 매우 크더라도 신경망이 이를 처리하여 의미 있는 결과를 얻을 수 있음을 보여준 것이다. 물론 알고리즘의 안정적 수렴을 위해 스마트한 기술을 도입하긴 했지만 DQN은 action space는 크지 않는 경우를 대상으로 하였다. 그러나 실제적 일에는 action space가 연속적이거나 dimension이 매우 큰 경우가 많으므로, DQN과 같이 action-value function이 최대가 되는 action을 선택하도록 하는 Q-learning 알고리즘을 그대로 사용하려면 먼저 생각할 수 있는 방법이 action space의 discretization과 같은 편법을 사용할 필요가 있다. 이 논문에서는 이러한 문제를 해결하기 위해 neural network actor 및 critic을 채용하여 state space와 action space가 모두 큰 dimension 또는 continuous space일 때 사용 가능하도록 한 것이다.
DDPG Algorithm의 특징
이 알고리즘의 특징이 DQN Algorithm의 특징과 유사할수 밖에 없는 이유는 결국 neural network function approximator를 사용하게 되면 생길 수 있는 문제를 태생적으로 가질 수 밖에 없기 때문이다(너무 많은 패러미터들 가진 함수는 학습시키기 어렵다). 그러므로, 학습에 사용되는 sample은 iid(independently and identically distributed) 특징을 가져야 한다. 이를 위해 사용한 방법이 DQN의 replay buffer이다.
같은 맥락에서 action value network 학습을 위해 target network를 별도로 두는 방법도 역시 이용되었다. 그러나 이 논문에서는 약간의 변형을 시도하였다. 일명 ‘soft’ target update방법으로 아래와 같이 target network의 parameter들이 보다 ‘soft’하게 변화하도록 했다.

신경망 학습에서 state/observation에 포함되는 여러 값들의 절대값의 order of magnitude문제에 의한 학습 성능 저하를 막기위해 사용하는 batch normalization도 적용하였다.
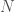
마지막으로, continuous action space에서 exploration이 지속적으로 이루어지는 방법에 관한 것이다. DDPG에서는 off-policy 학습방법을 사용하기 때문에 기술적으로 구현이 매우 쉬운 장점이 있으며, 이 논문에서는 behavior policy에 noise process 을 도입하고, noise process로 Ornstein-Uhlenbeck process를 사용하였다고 밝혔다.

https://arxiv.org/pdf/1811.07522.pdf
Stock Trading Strategy은 투자 회사에서 중요한 역할을 합니다. 그러나 복잡하고 역동적 인 주식 시장에서 최적의 전략을 얻는 것은 어렵습니다. 우리는 주식 거래 전략을 최적화하여 투자 수익을 극대화하기 위한 Deep Reinforcement Learning의 잠재력을 탐색합니다.
30 개의 주식이 우리의 주식으로 선택되며, 일일 가격은 훈련 및 거래 시장 환경으로 사용됩니다. 우리는 Deep Learning Agent를 훈련시키고 adaptive trading strategy을 얻습니다. Agent의 성과는 평가되고 다우 존스 산업 평균 및 전통적인 분 분산 포트폴리오 할당 전략과 비교됩니다. 제안된 Deep Reinforcement Learning은 Sharpe 비율과 누적 수익의 측면에서 두 개의 기준선을 능가하는 것으로 나타났습니다.
1. Introduction
수익성있는 Stock Trading Strategy는 투자 회사에게 필수적입니다. 자본 배분을 최적화하여 기대 수익과 같은 성과를 극대화하는 데 적용됩니다. 수익 극대화는 주식의 잠재적 수익 및 위험에 대한 추정치를 기반으로합니다. 그러나 애널리스트가 복잡한 주식 시장에서 모든 적합한 요인을 고려하는 것은 어려운 일입니다 [1-3].
하나의 전통적인 접근 방식은 [4]에서 설명한대로 두 단계로 수행됩니다.
먼저 주가의 기대 수익률과 주가의 공분산 행렬을 계산합니다. 포트폴리오의 고정 된 위험에 대한 수익을 극대화하거나 수익의 범위에 대한 위험을 최소화함으로써 최상의 포트폴리오 배분을 찾을 수 있습니다. 최상의 거래 전략은 최고의 포트폴리오 할당을 따라 추출됩니다. 그러나 관리자가 각 시간 단계에서 결정한 사항을 수정하고 예를 들어 거래 비용을 고려하기를 원할 경우이 방법을 구현하는 것은 매우 복잡 할 수 있습니다. 주식 거래 문제를 해결하기위한 또 다른 접근법은 Markov Decision Process (MDP)로 모델링하고 동적 프로그래밍을 사용하여 최적의 전략을 해결하는 것입니다. 그러나 이 모델의 확장 성은 주식 시장을 다루는 the large state spaces 때문에 제한적이다 [5-8].
위의 도전에 동기를 부여하여 복잡하고 역동적 인 주식 시장에서 최고의 트레이딩 전략을 찾기 위해 DDPG (Deep Deterministic Policy Gradient) [9]라는 깊이 보강 학습 알고리즘을 탐구합니다.
이 알고리즘은 크게 세 가지 주요 구성 요소로 구성된다 :
(i) actor-critic framework[10] – that models large state and action spaces
(ii) target network – that stabilizes the training process[11]
(iii) experience replay – 샘플 간의 상관 관계를 제거하고 데이터 사용을 늘립니다. DDPG 알고리즘의 효율성은 전통적인 분 분산 포트폴리오 할당 방법과 다우 존스 산업 평균 지수 (Dow Jones Industrial Average 1, DJIA)보다 높은 수익률을 달성함으로써 입증됩니다.
이 논문은 다음과 같이 구성됩니다. 섹션 2에는 주식 거래 문제에 대한 설명이 포함되어 있습니다. 3 장에서 우리는 주 DDPG 알고리즘을 운전하고 명기한다. 4 절에서는 데이터 전처리와 실험 설정을 기술하고 DDPG 알고리즘의 성능을 제시한다. 5 절에서 결론을 내린다.
2 Problem Statement
우리는 Markov Decision Process (MDP)로 주식 거래 프로세스를 모델링합니다.
그런 다음 maximization problem에 대하여 우리의 trading goal을 공식화합니다.
2.1 Problem Formulation for Stock Trading

주식 가격이 바뀌면 “hold”가 다른 포트폴리오 가치로 이어질 수 있습니다.
본 연구에서는 거래 시장의 확률 적 및 상호 작용 성을 고려하여 그림 1과 같이 주식 거래 프로세스를 Markov Decision Process (MDP)로 모델화 하였다.

주식 시장의 역 동성은 다음과 같이 설명됩니다. 우리는 시간 t를 나타 내기 위해 첨자를 사용하고, 주식 d에 대해 가능한 행동은 다음과 같다.

모든 매입 한 주식은 포트폴리오 가치의 마이너스 잔고가되어서는 안된다는 점에 유의해야합니다. 즉, 일반성을 잃지 않고 첫 번째 d1 종목에 대한 판매 주문이 있고 마지막 d2 종목에 대한 구매 주문이 있다고 가정하고, [1 : d1] +에서 pt [1 : d1] T를 만족해야한다고 가정합니다 [D-d2 : D] ≥ 0 일 때 bt + pt [D-d2 : D] T이다. 나머지 잔액은 bt + 1 = bt + pTt로 갱신된다.
그림 1은이 프로세스를 보여줍니다.
위에 정의 된 바와 같이, 포트폴리오 가치는 모든 보유 주식의 주식의 잔액과 합계로 구성됩니다. 시간 t에서 조치가 취해지고 실행 된 조치 및 주가 갱신에 따라 포트폴리오 값이 “포트폴리오 값 0″에서 “포트폴리오 값 1”, “포트폴리오 값 2″또는 “포트폴리오 값 3″으로 변경됩니다 “시간 (t + 1).
환경에 노출되기 전에 p0는 0시에 주가로 설정되고 b0는 거래에 사용 가능한 초기 자금입니다.
h와 Qπ (s, a)는 0으로 초기화되고, π (s)는 모든 상태에 대한 모든 동작간에 균일하게 분산됩니다. 그런 다음, Qπ (st, at)는 외부 환경과의 상호 작용을 통해 학습됩니다.
벨만 방정식에 따르면, 행동을 취하는 예상 보상은 보상 r (st, at, st + 1)의 기대치와 다음 상태 st + 1의 예상 보상을 더하여 계산됩니다. 수익률이 γ 배만큼 할인된다는 가정하에, 우리는

2.2 Trading Goal as Return Maximization

모델의 Markov 속성으로 인해 문제는 Qπ (st, at) 함수를 최대화하는 정책을 최적화하는 것으로 끝낼 수 있습니다. action-value 함수가 정책 결정자에게 알려지지 않았고 환경과의 상호 작용을 통해 학습해야하기 때문에이 문제는 매우 어렵습니다. 따라서 이 논문에서 우리는 이 문제를 해결하기 위해 Deep Reinforcement Learning 방법을 사용한다.
3 A Deep Reinforcement Learning Approach
우리는 투자 수익을 극대화하기 위해 DDPG 알고리즘을 사용합니다.
DDPG는 DPG (Deterministic Policy Gradient) 알고리즘 [12]의 개선 된 버전입니다.
DPG는 Q-learning [13]과 정책 구배 [14]의 프레임 워크를 결합합니다. DPG와 비교하여 DDPG는 신경 회로망을 함수 근사자로 사용합니다. 이 섹션의 DDPG 알고리즘은 주식 거래 시장의 MDP 모델에 대해 지정됩니다.

함수 근사를 수행하기 위해 신경 네트워크를 채택하는 DQN (Deep Q-network)을 사용하면 상태가 값 함수로 인코딩됩니다.
그러나 DQN 접근 방식은 작업 공간의 크기가 크기 때문에이 문제에 대해 다루기가 어렵습니다.
각 주식에 대한 실현 가능한 거래 행위는 개별 집합에 있고 전체 주식의 수를 고려하기 때문에 행동 공간의 크기는 기하 급수적으로 증가하여 “차원의 저주”[15]로 이어진다.
따라서 DDPG 알고리즘은이 문제를 해결하기 위해 상태를 결정적으로 동작에 매핑하는 데 제안됩니다.

DDPG와 마찬가지로 DDPG는 experience replay buffer R을 사용하여 전환을 저장하고 모델을 업데이트하며 경험 샘플 간의 상관 관계를 효과적으로 줄일 수 있습니다.

critic network 및 actor network가 experience buffer로부터의 transitions에 의해 업데이트 된 후, target actor network 및 target critic network는 다음과 같이 업데이트된다 :

4 Performance Evaluations
Alg 1에서 DDPG 알고리즘의 성능을 평가합니다.
결과는 DDPG 에이전트를 사용한 제안 된 방법이 다우 존스 산업 평균 및 전통적인 분 – 분산 포트폴리오 할당 전략보다 더 높은 수익을 달성 함을 보여줍니다 [16, 17].

4.1 Data Preprocessing
우리는 트레이딩 주식으로 2011 년 1 월 1 일의 다우 존스 30 주식을 추적 및 선택하고, 01/01/2009부터 2011/9/30까지의 과거 일일 가격을 사용하여 에이전트를 교육하고 실적을 테스트합니다. 이 데이터 세트는 Wharton Research Data Services (WRDS) [18]를 통해 액세스 한 Compustat 데이터베이스에서 다운로드됩니다.
우리의 실험은 훈련, 검증 및 거래의 3 단계로 구성됩니다.
훈련 단계에서 Alg. 1은 잘 훈련 된 거래 에이전트를 생성합니다.
그런 다음 유효성 검사 단계는 학습 속도, 에피소드 수 등과 같은 주요 매개 변수 조정을 위해 수행됩니다.
마지막으로 거래 단계에서 제안 된 계획의 수익성을 평가합니다. 전체 데이터 세트는 그림 3과 같이 이러한 목적으로 세 부분으로 나뉩니다.
2009 년 1 월 1 일부터 2014 년 12 월 31 일까지의 데이터를 교육에 사용하며, 2010 년 1 월 1 일부터 2010 년 1 월 1 일까지의 데이터를 유효성 검사에 사용합니다.
우리는 훈련 자료와 검증 데이터 모두에 대해 우리의 에이전트를 교육하여 사용 가능한 데이터를 최대한 활용합니다.
마지막으로 거래 데이터에 대한 에이전트의 실적을 테스트합니다. 거래 데이터는 2011 년 1 월 1 일부터 2018 년 9 월 30 일까지입니다. 거래 데이터를보다 잘 활용하기 위해 우리는 거래 단계에서 에이전트를 계속 교육하여 에이전트가 시장 역학에보다 잘 적응할 수 있도록 개선 할 것입니다.
4.2 Experimental Setting and Results of Stock Trading
우리는 DDPG agent가 훈련 된 일일 주가의 벡터로 30 개의 주식 데이터를 설정함으로써 환경을 구축합니다.
학습 속도 및 에피소드 수를 업데이트하기 위해 에이전트는 유효성 검사 데이터에서 유효성이 검사됩니다. 마지막으로 우리는 거래 데이터에 대해 에이전트를 운영하고 DJI (Dow Jones Industrial Average) 및 최소 분산 포트폴리오 할당 전략과 성능을 비교합니다.
결과를 평가하기 위해 최종 포트폴리오 값, 연간 수익률, 연간 표준 오류 및 샤프 비율이라는 네 가지 메트릭이 사용됩니다. 최종 포트폴리오 가치는 거래 단계의 마지막 시점의 포트폴리오 가치를 반영합니다. 연간 수익은 연간 포트폴리오 수익률을 나타냅니다. 연간 표준 오류는 우리 모델의 강건 함을 보여줍니다. 샤프 비율은 그러한 평가를 제공하기 위해 수익과 위험을 결합합니다 [19].
그림 4에서 우리는 DDPG 전략이 다우 존스 산업 평균과 최소 분산 포트폴리오 할당보다 훨씬 우월함을 알 수 있습니다. 표 1에서 알 수 있듯이 DDPG 전략은 연간 수익률 22.24 %를 달성하며 다우 존스 산업 평균 (Dow Jones Industrial Average)의 16.40 % 및 최소 분산 포트폴리오 할당의 15.93 %보다 월등히 높습니다. DDPG 전략의 샤프 비율 (sharpe ratio) 또한 훨씬 높으며, 이는 DDPG 전략이 다우 존스 산업 평균 및 최소 분산 포트폴리오 할당 모두를 상회하여 위험과 수익의 균형을 맞추는 것을 의미합니다. 따라서 결과는 제안 된 DDPG 전략이 벤치 마크 다우 존스 산업 평균 및 전통적인 분 – 분산 포트폴리오 배분 방법을 능가하는 거래 전략을 효과적으로 개발할 수 있음을 보여줍니다.

5 Conclusion
본 논문에서는 DDPG (Deep Deterministic Policy Gradient) 에이전트가 주식 거래 전략을 학습 할 수있는 가능성을 모색했다.
결과는 우리의 숙련 된 에이전트가 누적 수익률에서 다우 존스 산업 평균 및 최소 분산 포트폴리오 할당 방법보다 우월함을 보여줍니다.
Sharpe 비율에 대한 비교는 우리의 방법이 위험과 수익의 균형을 잡는 데있어서 다른 방법보다 훨씬 견고 함을 보여줍니다.
미래의 연구는 더 정교한 모델을 탐구하고, 더 큰 규모의 데이터를 다루고, 지능적인 행동을 관찰하고 예측 계획을 통합하는 흥미로운 일이 될 것이다.
