[참조 논문 및 사이트]
☞Deep Learning based Recommender System: A Survey and New Perspectives
☞Reinforcement Learning to Rank in E-Commerce Search Engine:Formalization, Analysis, and Application
☞Personalizing Session-based Recommendations with Hierarchical Recurrent Neural Networks
☞Wide & Deep Learning for Recommender Systems
☞Convolutional Matrix Factorization for Document Context-Aware Recommendation
☞Deep Neural Networks for YouTube Recommendations
☞ITEM2VEC: NEURAL ITEM EMBEDDING FOR COLLABORATIVE FILTERING
☞Document Context-Aware Recommendation
☞A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation

1.연관규칙분석(A Priori Algorithm)/ 장바구니 분석(Market Basket Analysis)
교과서에서 많이 보았을 알고리즘으로 현업에서는 아무도 사용하지 않는 알고리즘이지만, 추천 알고리즘의 시초격으로 간단하게 설명을하고 넘어가도록 하겠다. 장바구니 분석은 기본적으로 고객의 구매 이력을 바탕으로 A라는 제품을 많이 사는 사람이 B라는 제품을 많이 사더라와 같은 형태로 추론하는 것으로 이해할 수 있다.
| 조건절 | 결과절 | 지지도 | 신뢰도 | 향상도 |
|---|---|---|---|---|
| 참치캔 | 달걀, 라면 | 1 | 2.5 | 2.5 |
| 참치캔 | 달걀 | 1 | 1.5 | 1.5 |
| 라면,참치캔 | 달걀 | 1 | 1 | 1 |
주어진 데이터에서 위와 같은 결과를 추출하여 참치캔을 산 사람에게 달걀을 추천하는 식으로 활용한다고 이해할 수 있겠다. 여기서 나오는 지지도(support)와 신뢰도(confidence), 향상도(lift) 는 아래와 같이 정의할 수 있다.
- 지지도(support) s(X→Y) = X와 Y를 모두 포함하는 거래 수 / 전체 거래 수 = n(X∪Y) / N
- 신뢰도(Confidence) c(X→Y) = X와 Y를 모두 포함하는 거래 수 / X가 포함된 거래 수 = n(X∪Y) / n(X)
- 향상도(Lift) = 연관규칙의 신뢰도/지지도 = c(X→Y) / s(Y)
참조 : https://ratsgo.github.io/machine%20learning/2017/04/08/apriori/
2.협업필터(Collaborative Filtering)

협업필터는 고객의 구매 이력 혹은 별점등의 이력을 기반으로 유사한 고객그룹 혹은 제품 그룹을 찾아 추천하는 방식을 말한다. 때문에 신규 고객에 대해서는 유사도를 구할 수 없는, Cold Start 문제 등이 존재하지만, 현재 딥러닝 기반의 추천 모델에서도 기본 개념으로서 사용되고 있다. 조금 더 자세히 설명해보면 우리가 가지고 있는 구매/추천 등 데이터는 위와 같은 형태의 Sparse Matrix 형태로 표현이 가능하고, 하나의 고객은 복수의 제품에 대한 선호도로 그 특성이 Feature형태로 표현이 가능하다. 이러한 Feature 간의 유사도를 통해 해당 User 는 Buy 하지 않았지만, 유사 그룹은 많이 Buy 한 물건을 추천하는 형태로 이루어 지는 것이 협업 필터링의 기본 개념이 되겠다.
위의 Matrix 가 매우 많은 User 와 제품에 대해서 표현된다고 생각해보면, 엄청나게 그 데이터 사이즈와 계산량은 커지게 될 것이다. 때문에 2000년대 Hadoop/Spark 분산처리와 결합을 통한 CF 기법이 많이 사용되고는 하였다.
여기서 실제 구현 방법은 크게 Memory Based와 Model Based 로 나누어 질 수 있다. 이 두 방법의 차이는 ML 을 사용하여 파라메터를 훈련하는지 아니면 그런 과정 없이 데이터를 해석하는지로 이해하면 되겠다.
- Memory Based : Euclidean, Cosine, Pearson 등 유사도 등 거리 측정 방법
- Model Based : Clustering(KNN 등), 차원축소(SVD,PMF,NMF,PCA 등) , Deep Learning 등

CF 개념의 데이터를 기반으로 다양한 연구가 이루어 지는데, 단순하게 Memory Based 방법으로 거리를 측정하는 방법부터, Matrix Decomposition 후 유사도를 구하는 방법, Matrix Decomposition 후 Deep Learning 에 Input 으로 사용하는 방법 등 다양한 방법이 적용 될 수 있겠다.
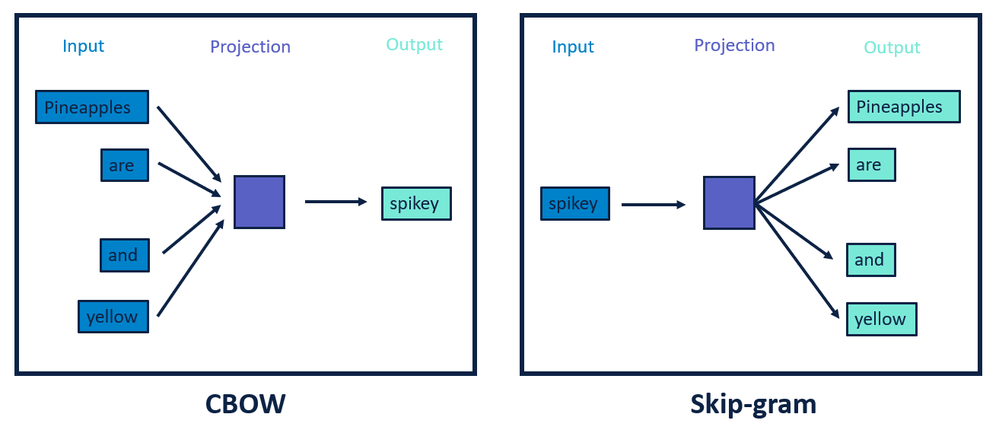
3.Item2Vec
장바구니 분석은 어떤 상품을 구입할때 같이 구매하는 상품이라는 관점에서 지지도(support)와 신뢰도(confidence), 향상도(lift) 를 Measure 로 사용하였다. CF(협업필터에서는) 사용자의 구매/추천 등의 데이터를 기반으로 그 유사도를 Measure 로 추천 상품을 결정하였다. (물론 MF 기반으로 Matrix 를 분리하고 상품 기준의 Feature 도 사용할 수가 있지만) Item2Vec라는 개념에서는 컨탠츠가 가지고 있는 “제목”,”음성”,”영상”,”설명”등 비정형 정보를 직접 Vector 화 하고 그 유사도를 기반으로 추천하기 위한 개념으로 이해하면 좋을 듯 하다.
Contents 자체의 Feature 를 도출하기 위한 방법은 Word2Vec, Doc2Vec, LDA2Vec, DEC(Autoencoder), Deep Learning Based Language Model 사용 등 다양한 방법이 있을 수 있으나, 2000년대 Item2Vec 에 영감을 준 연구는 단연 Word2Vec 이였을 것이다.
참조 : ITEM2VEC: NEURAL ITEM EMBEDDING FOR COLLABORATIVE FILTERING
4. Document Context-Aware Recommendation(CF + CNN, AutoEncoder .. Etc)

CF 와 CNN, AutoEncoder 등 Deep Learning 모델을 결합하는 형태의 연구들이 진행되었다. Item2Vec 에서 비정형 데이터를 추천에 활용하고자 하는 연구로부터 기존의 연구와의 결합형태로 많이 진행이 되었다고 생각된다. 이 시기까지도 여전히 기존의 방법론에 Deep Learning 은 Feature 만 잘 뽑아 주면 된다는 생각이 많이 느껴진다.
위 구조를 간단하게 설명하면 아래와 같음
- Document Information 을 CNN 을 통해서 Feature 를 잘 추출 할 수 있도록 함
- CF 의 Spare 한 Matrix 을 Matrix Factorization을 통해 User 와 Item Vector 로 분리 가능
- 위의 Document 에서 추출한 Feature 를 Item Vector 로 사용함
- 특정 User Vector 를 알고 해당 User 의 CF Matrix 을 알고 있으니 Loss Function 구성이 가능해 짐
5. A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation

DSSM( A deep structured semantic model ) 계열의 연구들은 사용자의 검색/행동등을 Encoding 하고 각 Item에 대한 특성을 Encoding 한 후에 아래와 같이 Cosine 유사도를 통해 고객의 행동과 가장 유사한 상품을 추천하는 형태로 구성되어 있다. 훈련은 당연히 실제 구매/클릭한 상품의 경우 1 아니면 0으로 유사도와 CE 를 통해 훈련하는 형태가 될 것이다.
위 논문의 경우 기존 DSSM 에서 특정 분야에서의 고객의 소비 패턴은 다른 분야에서도 적용될 수 있을 것이라는 Cross-Domain 개념이 추가된 형태로 이해하면 좋을 듯 하다.
6. Deep Neural Networks for YouTube Recommendations
이 시기부터 급속도로 딥러닝 기반의 연구로 Phase 가 넘어가는 것으로 생각된다. 흐름 자체가 기존의 CF, CB 등의 개념에 종속되기 보다는 모든 데이터를 다 신경망에 넣고 예측을 하는 형태로 진행되며, 추천 관련 연구라기 보다는 딥러닝 관련 연구의 발전에 따라 해당 연구를 추천에 차용하고 복합적으로 적용하는 형태로 연구가 지속적으로 발전된다고 이해된다.

YouTube 추천에 사용된 알고리즘에 대한 연구로, 크게 두 부분으로 나누어 진다. 후보 추출 모듈과 랭킹 모듈이다.

위는 N 개의 후보 대상으로 압축하기 위한 모듈의 아키택쳐이다. Input 은 자신이 보았던 영화들의 Avg Feature 와 검색하였던 영상들의 Avg Feature 및 기타 성별, 지역 등 정형 데이터를 사용한다. Y 레이블은 좋아요 등의 Flag 가 아닌 끝가지 시청하였는지 여부를 사용한다. Output Layer 는 Extreme multiclass classification 이라고 표현하고 있는데, 모든 영화의 종류별로 볼 확률(0~1)을 구한다. Train 시에는 우리가 가지고 있는 Y Label 과의 CE 를 Loss 로 신경망을 훈련하며, Inference 시에는 마지막 Feature 를 각 영화별 Feature Index(훈련시에 Update)와 유사도 비교를 통해 추천을 실행한다. (Top K 개를 고르는 행위를 하게 된다)

이제는 1차로 추천된 목록을 Ranking 을 구하는 작업을 진행한다. 이 때에는 더 많은 수백개 이상의 요소들을 X 인자로 사용하여, 노출대비 얼마나 많이 시청하였는지를 Loss 로 하여 Real Time 으로 모델을 계속해서 훈련하여 사용한다. (고객이 실시간으로 추천 했을 때, 어떻게 반응하였는지를 다시 Serving 에 반영하는 것이 중요함, 그렇지 않으면, 그 고객이 마음에 들지 않는 추천 영상이 계속 추천 될 것임) 또, 이전에 봤던 영상들의 Avg 와 직전에 본 영상에 대한 Feature는 분리하여 Input 에 넣어주어 현재 영상을 보고 있는 순서에 따라 다른 영상을 계속 추천하기 위한 장치를 마련한다.
지금와서 보면 전체적으로 특별할 것도 없고 평이한 내용들이 진부한 나열로 보이기도 하지만, 그 당시에는 뭔가 기존의 틀을 깨고 딥러닝으로 End2End 추천 문제를 해결하고, 훈련과정과 사용과정을 Interactive 하게 설계하였다는 점에서 의미가 있었다.
7. Wide & Deep Learning for Recommender Systems

로지스틱 회귀 모델을 이용하여 추천 알고리즘을 작성하여 학습을 시킨 경우, 학습 데이타를 기반으로 상세화된 예측 결과를 리턴해준다. 예를 들어 검색 키워드 (프라이드 치킨)으로 검색한 사용자가 (치킨과 와플)을 주문한 기록이 많았다면, 이 모델은 (프라이드 치킨)으로 검색한 사용자는 항상 (치킨과 와플)을 추천해주게 된다. 즉 예전에 기억된 값 (Memorization된 값)을 통해서 예측을 하는데, 이러한 모델을 와이드 모델이라고 한다.
그러나 (프라이드 치킨)으로 검색한 사용자에게 같은 패스트 푸드 종류인 햄버거나 프렌치프라이등을 추천해도 잘 구매가 되지만 와이드 모델은 기존에 기억된 결과로만 추천을 하기 때문에 이러한 결과를 얻기가 어렵다.
뉴럴네트워크 모델의 경우 프라이드 치킨을 햄버거, 프랜치 프라이등을 일반화 시켜서 패스트 푸드로 분류하여 프라이드 치킨으로 검색을 해도 이와 같은 종류의 햄버거를 추천해도 사용자가 택할 가능성이 높다.
이러한 모델을 딥모델이라고 하는데, 딥 모델의 경우 문제점이, 너무 일반화가(under fitting) 되서 엉뚱한 결과가 나올 수 있다는 것인데, 예를 들어서 따뜻한 아메리카노를 검색했는데, 커피라는 일반화 범주에서 아이스 라떼를 추천해줄 수 있다는 것이다. 즉 커피라는 일반화 범주에서 라떼는 맞는 추천일 수 있지만, 따뜻한 음료를 원하는 사람에게 차가운 음료를 추천하는 지나친 일반화가 발생할 수 있다.

그래서 결국 Logistic 기반의 Wide 와 Deep Learning 기반의 Deep 을 동시에 Ensemble 하여 판단하면서, End2End Network 로 한번에 훈련할 수 있도록 Joint Training 개념을 적용하였다는 것이 이 논문의 핵심이 되겠다.
8. Personalizing Session-based Recommendations with Hierarchical Recurrent Neural Networks

이 논문에서의 핵심은 Session 이라는 개념이다. 전통적인 CF(협업필터) 방식등은 고객의 Log Term Favor 를 잘 표현할 수는 있으나, 최근의 소비에 강한 영향을 줄 수 있는 행동을 잘 반영하지 못하는 문제가 있을 수 있다. 여기서 Session 이라는 개념은 고객이 하나의 소비를 하기 전에 앞서 발생하는 일련의 순서와도 같은 것이다. 예를 들어 집을 산다고 하면, 자신의 집이 얼마인지 알아보고, 대출이 얼마 가능한지 알아보고, 매물을 찾아 보고 하는 일련의 행위를 하나의 그룹으로 합쳐서 Session 이라고 이야기 하고 있다. 하지만, 이렇게 Session 만 반영을 하게 되면, 고객의 Long Term Favor 를 또 잃어 버릴 수가 있다.

그래서 이 연구에서 제안하는 방식이 Session 단위 Encoding 을 위한 RNN 과 Long Term Favor 를 Encoding 하기 위한 RNN 을 계층적으로 사용하는 Hierarchical Recurrent Neural Networks 라고 이해하면 좋겠다.
9. TF-Ranking: Scalable TensorFlow Library for Learning-to-Rank

LTR(Learn to Rank) 를 Deep Learning 에 적용하기 위해서 최근 Tensorflow 에서도 관련된 Loss Function 을 제공하고 있는데, 아래와 같이 3가지의 Metric(MRR, ARP, NDCG) 와 Pointwise, Pairwise, Listwise 3가지 Loss Function을 교차로 성능을 평가한 결과를 제공하고 있다.


- 참조 : https://www.yumpu.com/en/document/read/33943335/1spz42p/90
- 참조 : https://towardsdatascience.com/introducing-tf-ranking-f94433c33ff
- 참조 : https://arxiv.org/pdf/1812.00073.pdf
딥러닝에 LTR(Learn to Rank)를 적용시 사용 가능한 조합은 크게 두개 축으로 설명될 수 있다. 어떤 평가 Metric 을 사용할 것인가와 어떤 Loss Function 을 사용할 것인가 이다. 우선 Loss Function 에 대한 부분을 살펴 보자. 아래의 Loss Function 이 각각 PointWise, PairWise, ListWise 에 대항하는 Loss Function 으로 이해하면 된다.

PointWise 에 해당하는 Loss 로는 우리가 카테고리 분류에 많이 사용하는 Cross Entropy 이며, 여기서 p 는 Softmax 가 아닌 Sigmoid 활성함수를 적용한 결과이고 Sigmoid 의 Input 은 위에서 이야기한 특정 Score Metric 의 결과로 이해하면된다. 실험 결과를 보면, Ranking 문제를 해결함에 있어서는 그리 효과적이지 않다.

PairWise 는 예를들어 실제 Label 의 Rank 가 A 상품>B상품 이라고 했을때, 예측한 결과가 B상품>A상품이라고 하면, 실제 결과와 다르기 때문에 Loss 를 증가 시켜 주어야 하는 것이고, B와 A 상품의 차이 만큼 Loss 의 Sum 이 증가되는 형태로 이애하면 된다. 실제와 동일하게 예측한 경우 I 함수가 (Indicator Function)이 0이 되기 때문에 Loss 는 증가하지 않는다.

ListWise 는 전체 List 의 순서가 얼마나 유사하느냐를 Loss 로 재현하면 되는 문제로 생각된다. Log(Softmax) Term 을 보면, Score 가 높으면 0에 가까워 지고 Score 가 적으면 -무한대로 가까워 지게 되어 있다. 거기에 Labled 된 Score 를 곱하는 개념으로 설계가 되어 있는데, 해석해보면 스코어가 높은걸 높게 예측하면 Loss 가 0에 가까워 지고 높은걸 낮게 예측하면 Loss 가 -무한대 * (-) 로 Loss 가 커지게 된다.

NDCG 는 검색엔진에서 노출 순서가 얼마나 잘 맞는지를 평가하기 위한 방법으로, 크게 Gain(얼마나 잘 맞춘 것인지), Position Discount(후순위는 별로 중요하지 않아), Normalize(0~1사이의 값으로 표현) , Cumulating(순서대로 누적합) 크게 4가지 부분으로 이루어져 있다.

얼마나 잘 순서를 추천했는지에 따라서 위와 같은 형태로 점수를 부여한다.

Max DCG 는 주어진 Label 로 Ordering 했을때 얻을 수 있는 최대 점수로 생각하면 되며, Normalize 를 통해 0~1사이의 값으로 각각에 대한 점수가 계산된다. 이 점수를 위에서 설명한 Loss Function 에 적용하면 된다. 이러한 방법론을 통해 Ranking 문제에 있어서 기존의 Cross Entropy 를 적용하는 것보다 더 좋은 성과를 보여주었다.
10. Reinforcement Learning to Rank in E-Commerce Search Engine: Formalization, Analysis, and Application

이 논문의 핵심은 기존의 추천 알고리즘들이 사용자의 소비 패턴은 위의 그림처럼 각각의 Session은 다른 Session 들과 높은 연관성을 가지고 있으나, 그러한 연관성을 잘 반영하지 못하고 있는 문제가 있어 RL(강화학습)을 적용하여 그 연관성을 잘 반영하고자 하는 것이다.

이 논문에서는 MDP(Markov Decision Process)를 기반으로 몇 가지 특성을 추가한 Search Session MDP 라는 방법을 정의하고 있다. (위는 MDP 의 일반적인 구조) , SSMDP 에서 각 요소는 아래와 같이 정의 된다.
- Agent 는 Search Engine 으로 Ranking Engine 이라고 생각하면 된다.
- Environment 는 쇼핑몰이 가지고 있는 모든 고객의 쇼핑 패턴 정보이다.
- State 는 크게 3개로 정의(계속 쇼핑, 쇼핑 중단, 물건 구매), 이전 State 와 Action 으로 확률 판단
- Action은 사용자에게 추천하는 상품 목록이다.
- Reward 는 실제 사용자가 물건을 구매 했을 때 추천한 물건의 가격이 된다.
위의 정의를 기본으로 실제 하나의 Session 을 구성해 보면 아래와 같이 시각화하여 설명할 수 있다

- C 는 Continue 상태로 계속 다른 검색을 진행하는 non-terminal state 이다
- B 는 Buy 상태로 물건을 구매하는 terminal state 이다
- L 은 Leave 상태로 검색을 종료하고 떠나는 terminal state 이다
- Red h 는 과거 출력된 Item 목록 이력 정보 이다
- Blue 는 각 State 로 전이할 확률이다.
이 다음에 B, C , L 중에 어떤 State 로 전이할 것이지에 대한 확률은 아래와 같이. 이전 State 와 Action 에 따른다고 본 논문에서 증명하고 있다. (증명은 논문에서 참조)

Reward 는 아래와 같이 Buy State 로 갔을 때, h 는 추천 결과, m(h) 는 추천 가격을 반영한 결과이다.

그리고 마지막으로 Reinforcement Learning 을 통해 훈련을 진행하는데, 예측해야 하는 Action 이 많기 때문에 아래의 표에서 보는 것처럼 Value방식과 Policy 방식을 모두 취하는 Actor-Critic 방법을 사용한다.

그렇게 하려고 하면 Q Function 과 J Function 이 모두 정의되어야 하는데, 아래과 같이 정의된다. J Function 은 일반적으로 강화학습에서 사용하는 Policy Gradient 최종 공식과 큰 차이가 없는 것으로 보이며, Q Function 은 위에서 정의한 변하는 State 에 따른 Reward 를 반영한 형태로 구성이 되는 것을 볼수 있다. (Advantage 개념은 안보이는거 같기는 한데..) 앞에 Term 은 Buy 하는 경우, 예상 판매가이고 뒤에 Term 은 계속 쇼핑을 하는 경우 미래에 기대되는 Reward 이다.


이제 아래 수도코드와 같이 훈련을 진행하는데, 여기서 세타는 파이(폴리시)에 대한 파리메터이고, W 는 Q(Value) 에 대한 파라메터 이며, 세타는 일방적인 강화학습의 Policy 훈련과 마찬가지로 세타 + 러닝레이트*Gradient(J)*Q 로 훈련하고, Q Function 은 TD 방식으로 이전과 이후의 Value 의 차이를(MSE) 이용하여 훈련하는 것으로 보인다.
하나의 Session(T Time) 까지 각 Step 에 따라 Gradient w와 세타를 축적하다가(Sum) 한 Session 이 끝나면, T 로 나누어 Update 하는 형태로 훈련이 진행된다.

11. Personalized Re-ranking for Recommendation

이 논문은 기본적으로 Item 추천 순위의 Re-Ordering 의 형태를 가지고 있다. 이 논문에서의 핵심 아이디어는 두 가지로 생각된다. 하나는 Item 간의 관계를 해석할 수 있는 모델 구조를 사용하겠다. (그래서 양방향의 관계를 잘 학습할 수 있는 Attention 기반의 Transformer 아키택쳐가 적합하다고 이야기 함). 하나의 Item을 추천하는 것이 아닌 연관된 Item 들도 추천을 할 수 있는 형태를 생각한 것 같음(ex: 술, 오징어, 담배 와 같이)

위의 내용을 가지고 Re-Ranking 에 대한 Loss 를 정의하면 위와 같이 될 것이다.(이걸 LTR: Learn to Rank 라고 부른다고 함) 하지만 여기에서 빠진 것이 있는데, 이전의 연구들에서 사용되던, 개인의 선호 및 Session 이라고 이야기한 최근 조작 정보 등 정보가 Re-Ranking 판단시 적용되지 않게 된다.

그래서 PV 라는 ITEM 별로 개인의 성향 및 조작 정보를 Input 으로 Pretrained 모델을 거쳐 나온 Feature 를 사용하는 방법을 제안하고 있다. 해당 모델의 위 그림의 C 에 해당하는 부분인데, Input 으로 개인에 대한 정보 + 개인의 Action History + Item Vector 를 넣고 Output 으로 해당 Item 을 클릭 했는지 여부로 아래와 같은 Loss Function 으로 모델을 Pretrain 하고 (b) 모델을 훈련시 item,user 별로 마지막 Layer 의 값을 PV 로 추출하여 사용한다.
조금은 의문스러운 부분은 Session 이라는 개념의 정보는 분명히 시계열 성격을 가지고 있고, 가장 최근의 사용자의 Action 은 과거의 Action 보다 분명 더 큰 영향력을 가지고 있어, 그러한 부분을 잘 반영할 필요가 있다과 생각되는데 그런한 개념이 잘 설명되지는 않는 것 같다는 생각이 든다..