Wide & Deep Learning for Recommender Systems의 논문과
Tensroflow Submit 2017 발표 자료를 참조 하여 정리
- 개요
- Wide에 대한 이해
- Deep에 대한 이해
- Feature Embedding
- Joint Training(Wide + Deep)
- How to serve
- 추천 시스템에 적용 결과
1.개요
일반화(Deep)와 기억(Wide)의 개념을 적용하여 범용적으로 추천을 해주는 Google Play에 적용된 알고리즘



독수리는 난다 / 비둘기는 난다 / 팽귄은 날지 못한다 Wide -> Memorization (각각의 특징을 기억함)
날개가 있는 동물은 날수 있다 Deep -> Generalization (특징을 일반화함)
날개가 있는 동물은 날 수 있지만 팽귄은 예외적으로 날지 못한다 Wide + Deep -> 일반화+기억
2. Wide에 대한 이해

Feature의 구성(Sparse한 특징을 잘 기억하게 구성됨)
※ 
일차함수()와 같은 형태를 말함


Crossed Feature란?
P란 App을 설치한 사람은 K라는 앱을 설치할 수도 있다는 각 Feature가 연관된것을 그룹핑함
P와 K를 따로 학습시키지 않고 연광성이 높기에 같이 학습을 시킴
Sparse Interaction의 문제가 있음 기억하는 값들만 잘찾기에 결국은 Overfitting으로 이어짐

[치킨을 주문한 사람은 치킨과 와플만 추천받음, 치킨밥도 살수있는데..]
Tensorflow의 estimator객체인 tf.estimator.LinearClassifier을 사용하여 간단히 구현 가능
(tf.contrib.learn.estimator은 deperecated : v1.7기준)

[참조 : https://www.tensorflow.org/api_docs/python/tf/estimator/LinearClassifier#class_linearclassifier]
3. Deep에 대한 이해

Feature의 구성(General한 특징을 바탕으로 일반화 시킴)

[치킨을 검색하니 새우볶음밥까지 추천..]
각각의 Feature가 Embedding됨에 따라 각 특징들이 추사상화 되면서 Underfitting되는 경향이 있음
마찬가지로 tf.estimator.DNNClassifier로 쉽게 구현
[참고 : https://www.tensorflow.org/api_docs/python/tf/estimator/DNNClassifier]
4. Feature Embedding


5. Joint Training (Wide + Deep)


Joint Training : Ensemble와는 다르게 동시에 학습하여 서로를 보완함
(ensemble의 경우 각각을 학습 후 예측시 결합)
factorization machines(Reference 논문)
마찬가지로 tf.estimator.DNNLinearCombinedRegressor로 쉽게 구현
6. How to Serve

구글은 백만개가 넘는 App들이 관리되고 있으며 사용자들은 App을 설치하고자 할때
추천 시스템을 통해 App List 중에서 Ranking에 따라 추천하게되는데
사용자의 검색패턴 (Query)과 실재 사용자가 설치한 App(Items)의 정보를 기본으로
User Actions (클릭, 구매)등을 통해 학습한 모델과 검색 조건을 결합하여 추천을 함
P(y|x)로 값이 확률값에 따라 소팅하여 Listing 됨
일반적으로 App은 사용자 Feature(나라, 인구, 종교), 주요 Feature(기기, 시간, 날짜)
특징 Feature(앱통계, 앱시기)로 추천
Logs Data를 바탕으로 학습한 모델을 Ranking을 통한 추천(Items)
(Logs Data = 사용자의 질문과 패턴 그리고 설치한 App을 기반으로한 Data)
사용자의 질의 영역(Query)는 기존 DB에 저장된 검색을 이용


import tensorflow as tf
# Continuous columns
age = tf.feature_column.numeric_column('age')
education_num = tf.feature_column.numeric_column('education_num')
capital_gain = tf.feature_column.numeric_column('capital_gain')
capital_loss = tf.feature_column.numeric_column('capital_loss')
hours_per_week = tf.feature_column.numeric_column('hours_per_week')
education = tf.feature_column.categorical_column_with_vocabulary_list(
'education', [
'Bachelors', 'HS-grad', '11th', 'Masters', '9th', 'Some-college',
'Assoc-acdm', 'Assoc-voc', '7th-8th', 'Doctorate', 'Prof-school',
'5th-6th', '10th', '1st-4th', 'Preschool', '12th'])
marital_status = tf.feature_column.categorical_column_with_vocabulary_list(
'marital_status', [
'Married-civ-spouse', 'Divorced', 'Married-spouse-absent',
'Never-married', 'Separated', 'Married-AF-spouse', 'Widowed'])
relationship = tf.feature_column.categorical_column_with_vocabulary_list(
'relationship', [
'Husband', 'Not-in-family', 'Wife', 'Own-child', 'Unmarried',
'Other-relative'])
workclass = tf.feature_column.categorical_column_with_vocabulary_list(
'workclass', [
'Self-emp-not-inc', 'Private', 'State-gov', 'Federal-gov',
'Local-gov', '?', 'Self-emp-inc', 'Without-pay', 'Never-worked'])
# To show an example of hashing:
occupation = tf.feature_column.categorical_column_with_hash_bucket(
'occupation', hash_bucket_size=1000)
# Transformations.
age_buckets = tf.feature_column.bucketized_column(
age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])
# Wide Columns
base_columns = [
education, marital_status, relationship, workclass, occupation,
age_buckets,
]
crossed_columns = [
tf.feature_column.crossed_column(
['education', 'occupation'], hash_bucket_size=1000),
tf.feature_column.crossed_column(
[age_buckets, 'education', 'occupation'], hash_bucket_size=1000),
]
# Deep Columns
deep_columns = [
age,
education_num,
capital_gain,
capital_loss,
hours_per_week,
tf.feature_column.indicator_column(workclass),
tf.feature_column.indicator_column(education),
tf.feature_column.indicator_column(marital_status),
tf.feature_column.indicator_column(relationship),
# To show an example of embedding
tf.feature_column.embedding_column(occupation, dimension=8),
]
7. 추천시스템 적용 결과
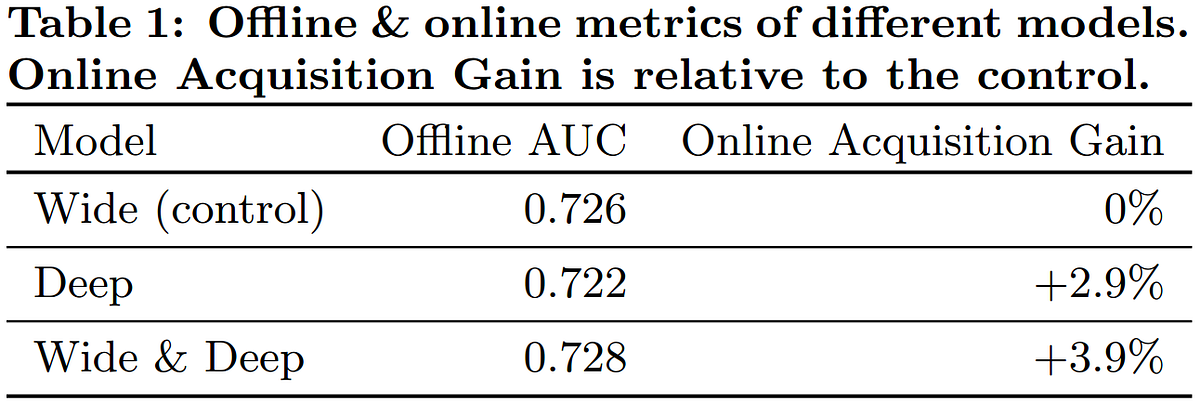
※ Area under the curve (AUC)

논문에서는 10ms 미만의 성능을 제공하기 위해 multithreading parallelism을 구현
(추론 시 모든 후보군을 한번에 처리하지 않고 Small Batch를 병렬로 처리)

학습된 Model이 Server에 Load 된 후 각각의 후보 Data를 받아 Wide & Deep Model을 통해 Inference 후 Score를 매겨 최고점수에서 최저점까지 Sorting 후 보여줌
끝